本篇目录:
- 1、如何在kafka-python和confluent-kafka之间做出选择
- 2、Kafka使用场景
- 3、常见的大数据采集工具有哪些?
- 4、大数据分析一般用什么工具分析
- 5、不要再苦没有合适的kafka管理平台,给你分享10款kafka管理工具
- 6、大数据分析需要哪些工具
如何在kafka-python和confluent-kafka之间做出选择
1、用confluent-kafka替换kafka-python非常简单。confluent-kafka使用poll方法,它类似于上面提到的访问kafka-python的变通方案。
2、我也简单的了解了下,有个逻辑集群的概念,对于规模比较大的kafka集群管理还是挺好的,不过,这里比较高端的特性都是不开源的,必须商业版才能用。
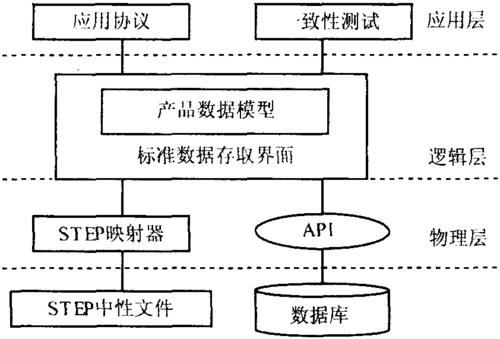
-图1")
3、这个延迟需要体现在两个boker间主备数据同步。在默认情况下,两个boker只有一个线程负责数据的复制。根据经验,每个boker上的分区限制在100*b*r内(b指集群内boker的数量,r指副本数量)。
4、一般是先会创建一个主题,比如说TopicA,有三个分区,有两个副本(leader+follower总共2个),同一个分区的两个副本肯定不在一个服务器。
5、Kafka可以作为分布式系统的一种外部提交日志。日志有助于在节点之间复制数据,并充当故障节点的重新同步机制,以恢复它们的数据。Kafka的日志压缩特性支持这种用法。在这种用法中,Kafka类似于Apache BookKeeper项目。
-图2")
Kafka使用场景
实时处理:Kafka可以实现实时的数据处理和推送,支持实时日志处理和大数据处理等场景。劣势 复杂性:Kafka的架构和设计较为复杂,需要相关技术人员具备深入的理解和掌握。
使用场景:笔者主要是用来做日志分析系统,其实Linkedin也是这么用的,可能是因为kafka对可靠性要求不是特别高,除了日志,网站的一些浏览数据应该也适用。
Kafka的consumer读取队列信息,并一定的处理策略,将获取的信息更新到数据库。完成数据到数据中心的存储。数据中心的数据需要共享时,kafka的producer先从数据中心读取数据,然后传入kafka缓存并加入待消费队列。
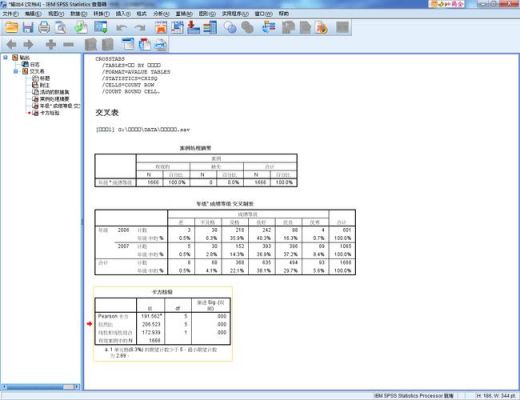
-图3")
Kafka不适合的场景有小规模应用、延迟敏感的应用程序等。如果您的应用程序规模较小且只有少量的消息传递需求,那么Kafka可能过于复杂和冗余。
常见的大数据采集工具有哪些?
1、Scrapy是一款基于Python的高性能网络爬虫框架,它具有强大且灵活的数据提取能力,同时也支持多线程和异步操作的特性。Scrapy将爬取、数据提取和数据处理等流程集成在了一个框架中,能极大地提高爬虫的开发效率。
2、KNIME 开源数据分析平台。你可以迅速在其中部署、扩展和熟悉数据。 Python 一种免费的开源语言。关于有哪些好用的大数据采集平台,青藤小编就和您分享到这里了。
3、日志收集:日志系统中定制各类数据发送方,用于收集数据。
4、八爪鱼采集器是一款功能强大的大数据采集工具。它可以帮助用户快速抓取互联网上的各种数据,包括文字、图片、视频等多种格式。八爪鱼采集器使用简单且完全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取。
5、NSLOOKUP nslookup命令几乎在所有的PC操作系统上都有安装,用于查询DNS的记录,查看域名解析是否正常,在网络故障的时候用来诊断网络问题。信息安全人员,可以通过返回的信息进行信息搜集。
6、使用数据采集工具可以使企业更精准地了解其用户,提高客户转化率,同时也可以为企业提供有效的运营和市场分析数据。
大数据分析一般用什么工具分析
1、FineReport FineReport是一款纯Java编写的、集数据展示(报表)和数据录入(表单)功能于一身的企业级web报表工具,只需要简单的拖拽操作便可以设计复杂的中国式报表,搭建数据决策分析系统。
2、Rapidminer目前备受瞩目,且已经成为众多知名数据科学家心目中的可靠工具。 Cassandra Apache Cassandra 是另一款值得关注的工具,因为其能够有效且高效地对大规模数据加以管理。
3、Excel:日常在做通报、报告和抽样分析中经常用到,其图表功能很强大,处理10万级别的数据很轻松。UltraEdit:文本工具,比TXT工具好用,打开和运行速度都比较快。
4、当前用于分析大数据的工具主要有开源与商用两个生态圈。开源大数据生态圈:Hadoop HDFS、HadoopMapReduce, Hbase、Hive 渐次诞生,早期Hadoop生态圈逐步形成。. Hypertable是另类。
不要再苦没有合适的kafka管理平台,给你分享10款kafka管理工具
1、kafka-console-ui(kafka可视化管理平台)一款轻量级的kafka可视化管理平台,安装配置快捷、简单易用。界面风格有点类似rocketmq-console。
2、bootstrap.servers 表示 Kafka 集群 。 如果集群中有多台物理服务器,则服务器地址之间用逗号分隔, 比如” 19161 :9092,19162:9092” 。
3、一般而言,手动调整、系统自动分配分区和添加分区之后,都需要调用 Reassign Partition 。kafka manager 能够获取到当前消费 kafka 集群消费者的相关信息。
4、Spark 提供了用于执行基本 1/0、调度和分派等任务的应用程序接口,并提供了同样开源的流处理平台。特别要提的是 Apache Kafka 代码是 Java 和 Scala 编写的。
大数据分析需要哪些工具
1、FineReport FineReport是一款纯Java编写的、集数据展示(报表)和数据录入(表单)功能于一身的企业级web报表工具,只需要简单的拖拽操作便可以设计复杂的中国式报表,搭建数据决策分析系统。
2、当前用于分析大数据的工具主要有开源与商用两个生态圈。开源大数据生态圈:Hadoop HDFS、HadoopMapReduce, Hbase、Hive 渐次诞生,早期Hadoop生态圈逐步形成。. Hypertable是另类。
3、大数据分析工具有:R-编程 R 编程是对所有人免费的最好的大数据分析工具之一。它是一种领先的统计编程语言,可用于统计分析、科学计算、数据可视化等。R 编程语言还可以扩展自身以执行各种大数据分析操作。
4、OpenRefine 这是一款高人气数据分析工具,适用于各类与分析相关的任务。这意味着即使大家拥有多种不同数据类型及名称,这款工具亦能够利用其强大的聚类算法完成条目分组。在聚类完成后,分析即可开始。
5、Hadoop Hadoop 是一个能够对大量数据进行分布式处理的软件框架。但是 Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。
6、下面小编就对大数据分析工具给大家好好介绍一下。首先我们从数据存储来讲数据分析的工具。
到此,以上就是小编对于kafka 监控的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏