本篇目录:
- 1、Spark依赖包加载顺序
- 2、spark3.0.0版本中sparksql中创建dataframe和执行sql的入口是
- 3、SparkSQL同步Hbase数据到Hive表
- 4、大神求助,IntelliJ运行Scala程序问题
- 5、spark进入txt文件的命令
- 6、org.apache.spark.api.java.optional在哪个包下
Spark依赖包加载顺序
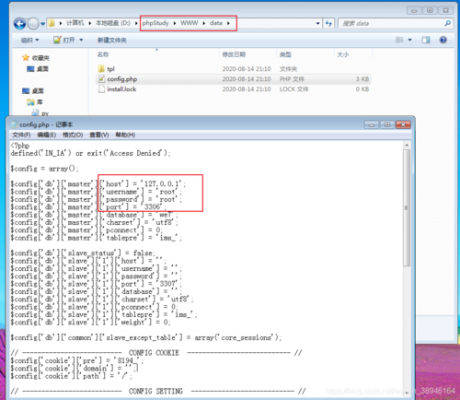
第一: 通过【Dependencies】,可视化界面操作点击Dependencies标签页。点击【add】按钮 输入我们想添加的jar包名字进行搜索.就会出现下图中所示。
启动Spark应用程序:通过设置PYSPARK_PYTHON环境变量来使用自己打包的Python环境启动Spark应用程序。
-图1")
在“File|Project Structure|Libraries”窗体中点击绿色+号,选择“Java”,在弹出的窗体中选择“Spark”的安装目录,定位到Spark\jars目录,点击“OK”,把全部jar文件引入到项目中。
DAGScheduler负责将任务转化为DAG(有向无环图)形式,并根据数据依赖关系进行任务划分和调度。而TaskScheduler则负责将DAG中的任务分发给集群中的各个节点进行执行。
SPARK_YARN_APP_JAR是自己程序打的jar包,包含自己的测试程序。程序中加入hadoop、yarn、依赖。
-图2")
spark3.0.0版本中sparksql中创建dataframe和执行sql的入口是
SparkSession。SparkSQL介绍说明,sparksql的程序入口是SparkSession。SparkSQL作为ApacheSpark中的一个模块,将关系处理与SparkAPI集成在一起。它是专为涉及大规模数据集的只读联机分析处理(OLAP)而设计的。
Spark SQL 中所有相关功能的入口点是 SQLContext 类或者它的子类, 创建一个 SQLContext 的所有需要仅仅是一个 SparkContext。
创建 SQLContext Spark SQL 中所有相关功能的入口点是 SQLContext 类或者它的子类, 创建一个 SQLContext 的所有需要仅仅是一个 SparkContext。
-图3")
SparkSQL同步Hbase数据到Hive表
1、Hive 跑批 建表 默认第一个字段会作为hbase的rowkey。导入数据 将userid插入到列key,作为hbase表的rowkey。
2、ImmutableBytesWritable.class, Result.class);在Spark使用如上Hadoop提供的标准接口读取HBase表数据(全表读),读取5亿左右数据,要20M+,而同样的数据保存在Hive中,读取却只需要1M以内,性能差别非常大。转载,仅供参考。
3、Hive是一种基于HDFS的数据仓库,并且提供了基于SQL模型的,针对存储了大数据的数据仓库,进行分布式交互查询的查询引擎。
大神求助,IntelliJ运行Scala程序问题
可能程序不兼容, 可以更换个版本试试。另外建议参考下程序对配置的要求。或者右键需要运行的程序 选择兼容性 用兼容模式运行试试。
进入设置菜单。2 点击安装JetBrains plugin 3 输入scala查询插件,点击安装 说明:我的IDEA已经安装,所以这里面没有显示出来安装按钮,否则右边有显示绿色按钮。
进入新页面后,在上方的搜索框中输入 Scala,选择Scala 这个插件,点击右侧边栏中的 Install Plugin 按钮,然后重启Intellij IDEA。
Scala是一门现代的多范式编程语言,志在以简练、优雅及类型安全的方式来表达常用编程模式。它平滑地集成了面向对象和函数语言的特性。Scala是面向对象的:Scala是一个纯面向对象语言,在某种意义上来讲所有数值都是对象。
网上和目前出版的书中讲解是spark0以下版本,采用的是把sparkle核心文件(如:“spark-assembly-0-hadoop0.jar”)拷贝到Interllij IDEA安装目录下的Lib目录下,再使用Spark。
安装Scala插件:点击『Install JetBrains plugin』按钮,查找Scala关键词,找到后安装。
spark进入txt文件的命令
windows上spark shell读取本地文件时,需要在文件地址前加“file:///”文本文件的后缀要有。由于不知道默认读取位置,因此建议使用绝对路径。
具体操作步骤:准备Spark程序目录结构。编辑build.sbt配置文件添加依赖。创建WriteToCk.scala数据写入程序文件。编译打包。运行。参数说明:your-user-name:目标ClickHouse集群中创建的数据库账号名。
文件不存在:确保文件实际存在于指定的路径中,如文件不存在,则会导致错误。权限不足:确保程序运行的用户有足够的权限访问文件,权限不足,则会导致错误。
hadoop包括hdfs、mapreduce、yarn、核心组件。hdfs用于存储,mapreduce用于计算,yarn用于资源管理。 spark包括spark sql、saprk mllib、spark streaming、spark 图计算。saprk的这些组件都是进行计算的。
org.apache.spark.api.java.optional在哪个包下
1、java.和javax。在Java中,API接口通常是通过Java类库来实现的,JavaSEAPI接口通常被组织在java.和javax.包中,JavaEEAPI接口通常被组织在javax.和org.包中,而JavaMEAPI接口通常被组织在javax.microedition.*包中。
2、Spark集群处理 斯卡利可以与Spark集群结合使用,实现大规模数据处理。可以使用Scala的SparkAPI进行数据处理。
3、在你不知道要导入哪个包的时候可以去查一下Java api文档,找到你要用的对象,然后看看是在哪个包下的,然后对应导进去就可以了。如果你使用eclipse来做开发的话,只要你写出对象的名字,工具就会自动为你导入对应的包的。
4、在jboss安装目录的/modules/javax/jms/api/main目录下,也可以找到 第二个办法,好像更方便一点。
5、java.sql。根据相关资料显示jdbcapi主要位于java.sql包里,不在java.jdbc,java.util和java.lang里。
到此,以上就是小编对于sparkreadjson的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏